
Compiling the NetBSD kernel as a benchmark
 For a while, I've been compiling my own NetBSD kernel. Just for a few options, mainly CARP, at first for my Raspberry Pis, and at the moment for paravirtualized Xen domUs. Compiling a custom NetBSD kernel is a very easy task, it's just a matter of 3 main steps :
For a while, I've been compiling my own NetBSD kernel. Just for a few options, mainly CARP, at first for my Raspberry Pis, and at the moment for paravirtualized Xen domUs. Compiling a custom NetBSD kernel is a very easy task, it's just a matter of 3 main steps :
- getting the sources ;
- copying a configuration file, then modifying this copy ;
- and then using
build.shin order to compile the tools, then the kernel itself.
Something I really like about compiling the NetBSD kernel is that it can be easily done on a system not running NetBSD. In other words, NetBSD can be cross-compiled very easily. Even with another CPU architecture. I've been compiling NetBSD kernels for evbarm (RPi) or for amd64 from a Linux 64-bit system, or from an Intel Mac. Overall, a simple process.
While compiling NetBSD 9.1 for my domUs that currently needs CARP, some questions popped in my head :
- which of my desktop systems is the fastest to compile NetBSD ?
- do I need a high core count, or rather a high frequency, if not both ?
- do I need fast storage to get faster compilation times ?
So I decided to compile NetBSD on a few systems :
- what was at the time my main desktop computer, with a Xeon X5670 CPU and 24GB of RAM ;
- a mid-2012 non-retina 15 inches Macbook Pro, with a Core i7-3720QM CPU and 16GB of RAM ;
- another mid-2012 non retina Macbook Pro, with a 13 inches screen, a Core i5-3210M CPU and also 16GB of RAM.
The desktop was running the latest Fedora at that time (32 or 33 if I recall correctly) and the laptops were running macOS 10.15 Catalina, with all updates installed.
How did I test these systems ? I made a very basic shell script, that would compile the GENERIC kernel profile for the amd64 port, then clean the compile directory, and then do it again... each time increasing the number of make jobs, from 1 to 20 (sometimes 28). I also ran the same compilation from a ramdisk, in order to check storage speed. Although each system runs on a SATA-3 SSD drives, the desktop Xeon computer only had a SATA-2 controller.
Since build.sh is quite verbose, keeping tracks of compile times was a matter of redirecting the output in log files, then extract start and end dates.
Once the compiling jobs were done, I entered the results in a Libre Office Calc sheet, and got this result :
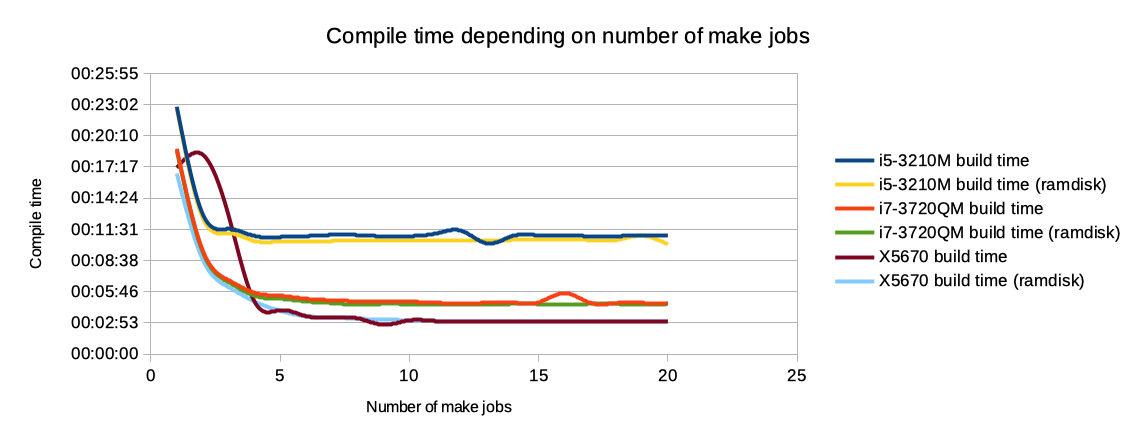
(Click here for full-res image)
So, what did I learn from this :
- despite being slightly older than the 3rd gen Core i5 and Core i7, the higher frequency of the Xeon X5670 seems to give it some advantage ;
- the compilation tools or the NetBSD kernel do not take advantage of running with more than 6 make jobs : more allocated jobs are a waste ;
- storage speed does not seems to be a bottleneck here ; trying to run the benchmark on a spinning hard drive could have been interesting ;
- compiling from a ramdisk does not seem to improve performance, but seems to improve stability : some numbers are off, for instance the compile time for 2 make jobs on the X5670.
Now, let's clearly answer my questions : - my fastest machine for compiling the NetBSD kernel is clearly the desktop system with the X5670 CPU ; - I get the fastest compilation with 6 make jobs, and a higher frequency seems to give better results ; - SATA SSD seems to do a decent enough job for storage, a ramdisk is not worth the (relative) hassle to setup.
Some other ideas to further enhance this benchmark :
- try to run benchmark on a CPU I can easily overclock, so I could really verify the impact of frequency alone ;
- try to run on a drive that is not the system drive (I guess this is one of the reasons some numbers are off) ;
- try to run multiple instances of each benchmark, and provide a chart for the means (that would reduce the impact of off numbers) ;
- try to run the benchmarks with a variety of operating systems on the same hardware, so I could determine wich one is the fastest, if there is a clear winner ;
- try to run the benchmarks with other kernel config files, to check the impact of removing/adding some features ;
- try to run the benchmarks with a more recent release of NetBSD, or -current ;
- try to run the benchmarks with clang instead of gcc.
I hope you enjoyed this post ! If you did, please share it on your favorite social networks :-)
Photo by Daniele Levis Pelusi on Unsplash.